
Using Cross-Validation to Solve Anscombe's Quartet
How can we use machine learning techniques to solve a classic statistics problem?
Anscombe’s Quartet is a collection of four data sets with nearly exactly the same summary statistics. It was developed by statistician Francis Anscombe in 1973 to illustrate the importance of plotting data and the impact of outliers on statistical analysis.
We can “solve” Anscombe’s Quartet with cross-validation in the sense that we can use statistics to determine which of the four data sets are actualy well represented by a linear model. Before we dive in, let’s take a look at the data sets. Seaborn provides an easy way to load Anscombe’s Quartet, as shown below.
# Standard Imports
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import KFoldLoad the data:
df = sns.load_dataset("anscombe")Plot the Quartet:
sns.lmplot(x="x", y="y", col="dataset", hue="dataset", data=df,
col_wrap=2, ci=None, palette="muted", height=4,
scatter_kws={"s": 50, "alpha": 1})
plt.gcf().suptitle("Anscombe's Quartet", x=0.5, y=1.02)
plt.tight_layout()
plt.show()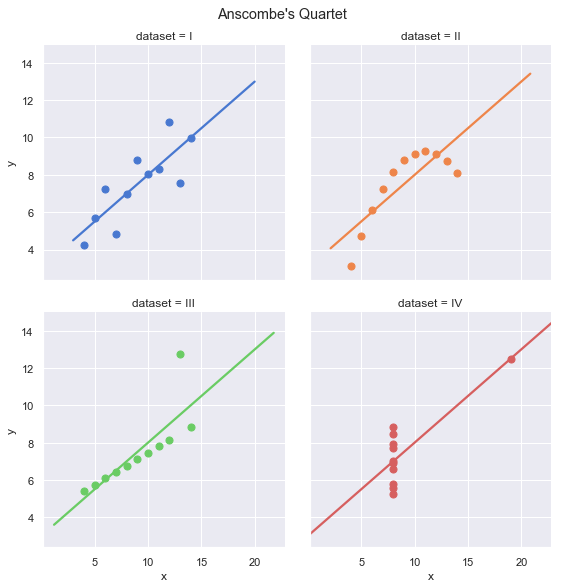
Visually, the four data sets look quite different. Group I is the only group that actually seems to be observations of a linear relationship with random noise. However, they all appear to have the same linear regression line.
Next, let’s calculate all the summary statistics, to show that they are identical.
grouped = df.groupby('dataset')
summary_results = pd.DataFrame(columns=['mean_x', 'mean_y', 'std_x', 'std_y', 'correlation', 'slope', 'offset', 'R2'])
for key in grouped.groups.keys():
data = grouped.get_group(key)
fit = LinearRegression().fit(data['x'].values.reshape(-1, 1), data['y'].values)
slope = fit.coef_[0]
offset = fit.intercept_
r2 = fit.score(data['x'].values.reshape(-1, 1), data['y'].values)
summary_results.loc[key] = (
grouped.mean().loc[key]['x'],
np.round(grouped.mean().loc[key]['y'], 2),
np.round(grouped.std().loc[key]['x'], 5),
np.round(grouped.std().loc[key]['y'], 2),
np.round(grouped.corr().loc[(key, 'x')]['y'], 3),
np.round(slope, 3),
np.round(offset, 2),
np.round(r2, 2)
)
summary_results| mean_x | mean_y | std_x | std_y | correlation | slope | offset | R2 | |
|---|---|---|---|---|---|---|---|---|
| I | 9.0 | 7.5 | 3.31662 | 2.03 | 0.816 | 0.5 | 3.0 | 0.67 |
| II | 9.0 | 7.5 | 3.31662 | 2.03 | 0.816 | 0.5 | 3.0 | 0.67 |
| III | 9.0 | 7.5 | 3.31662 | 2.03 | 0.816 | 0.5 | 3.0 | 0.67 |
| IV | 9.0 | 7.5 | 3.31662 | 2.03 | 0.817 | 0.5 | 3.0 | 0.67 |
As expected, all summary statistics are (nearly) identical. But what if we wanted to actually figure out which data set is best described by the linear model? We can do that with cross-validation.
The idea of cross-validation is simple, you randomly hold out some amount of your data, and fit the model with the reduced set. Then, you predict on the hold out set and look at the residuals. This process is repeated k times (“k-fold cross-validation”), so that every piece of data is in the test set exactly once. Finally, you calculate the standard deviation (RMSE) and mean (MBE) of all the residuals. A “good” model will have low RMSE and nearly zero MBE.
We can repeat this process for each of the four groups in Anscombe’s Quartet. Typically, we use cross-validation to pick the best model for a data set. In this case, we are finding which data set best fits a simple linear regresssion model.
hold_out_validation = pd.DataFrame(columns=['rmse', 'mbe'])
for key in grouped.groups.keys():
data = grouped.get_group(key)
X = data['x'].values.reshape(-1, 1)
y = data['y'].values
splits = KFold(n_splits=3, shuffle=True, random_state=42).split(X)
residuals = []
for train_ix, test_ix in splits:
fit = LinearRegression().fit(X[train_ix], y[train_ix])
y_pred = fit.predict(X[test_ix])
residuals.append(y[test_ix] - y_pred)
residuals = np.concatenate(residuals)
hold_out_validation.loc[key] = (np.linalg.norm(residuals) / np.sqrt(len(residuals)),
np.mean(residuals))
hold_out_validation| rmse | mbe | |
|---|---|---|
| I | 1.223902 | -0.050753 |
| II | 1.368272 | -0.145880 |
| III | 1.454342 | 0.208448 |
| IV | 2.006684 | 0.497576 |
plt.figure(figsize=(8, 5))
plt.stem(hold_out_validation['rmse'], label='RMSE')
plt.stem(hold_out_validation['mbe'], markerfmt='C1o', label='MBE')
plt.xticks([0, 1, 2, 3], list(hold_out_validation.index))
plt.legend()
plt.title("Cross-Validation Error Metrics on Anscombe's Quartet");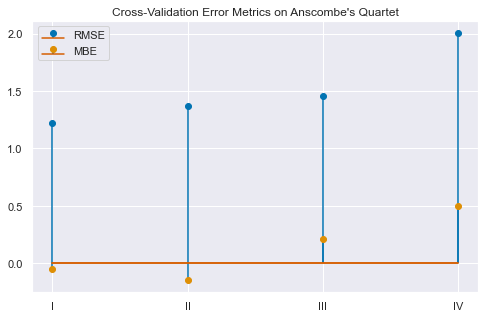
Perfect! Group I has the lowest RMSE and MBE in the Quartet.
Conclusions
Traditional measures such as correlation and coefficient of determination do not provide useful insight into which of the four groups is well characterized by a linear model. More generally, these measures are not appropriate for the task of model selection.
Model selection and validation procedures have been developed by the machine learning community as an alternative to these traditional measures. These newer procedures focus on the “predictive power” of a model. Typically these methods are deployed when trying to select between various fancy, non-linear ML models (say, different forms of a deep neural network).
However, the Anscombe’s Quartet example shows that these procedures are also quite useful when evaluating linear models. Cross-validation allows us to systematically determine that group I is best represented by a linear model with slope \(0.5\) and offset \(3.0\).